Forum Replies Created
-
AuthorPosts
-
I don’t understand why this would be a problem. Is there any better way?
Looks great!
In this example the libraries and projects are placed in the same directory. But in a real case of where this approach would be useful is this.
 Monkey1234567891011121314+ D:\Programming\MonkeyLibraries|+---+ GameEngine|+---+ Rameses3D|+---+ Collision|+---+ InputC:\Tests\Project1D:\MonkeyProjects\Project2E:\USBStorage\Project3P:\Programming\Project4
Monkey1234567891011121314+ D:\Programming\MonkeyLibraries|+---+ GameEngine|+---+ Rameses3D|+---+ Collision|+---+ InputC:\Tests\Project1D:\MonkeyProjects\Project2E:\USBStorage\Project3P:\Programming\Project4Yeah this is another good approach, I have seen that various open source projects are based on this approach, such as Blender. I would choose this one if the project was very streamlined and active, it would worth an appropriate file system setup.
Monkey123456789101112+MonkeyLibraries|+---+Rameses3D+MonkeyProjects|+---+Project1|+---+Project2|+---+Project3In my hard disk, everything is very unorganized – among various drives and cloud data. Also since I started organizing the projects based on date the file system relations become even more distributed.
I would hope that Monkey2 perhaps in the future might support include and lib parameters, so things become a little flexible there.
Monkey2 will get a 3D module soon (it’s now in the works and almost ready to roll). For building HTML5 games, this can be done with Emscripten, also there is support for iOS and Android devices as well.
> sending the vbo data once …
This technique reminds me of a batch renderer, where each drawing call is adding vertex data to the vertex buffer. However this optimization looks very interesting because you can save lots of data.
Now I got the idea for a workaround, to use full path imports: #Import “C:/___.monkey2”
However by doing some tests it seems that it doesn’t work, only relative paths work.
This looks like an Epic amount of code!
I could not even imagine how all these pieces can come together.
You upload them to the GPU right as VBOs (though in modern OpenGL this is the only way) or there’s another more advanced technique?
Great idea, this might help to understand speed issues better.
Perhaps also adding a trace command would help to register values to the profiler directly. For example currently you can use Print which is the default output stream, but is not “useful” in such cases as looking at numerical values.
I tested the program. Looks that it runs great.
I wonder also if there’s a good strategy to interpret Windows API data structures. They look like that they are over complicated for no reason.
Now I think that I would simply do a wrapper module in C to mess with the Win API and then expose only the good parts.

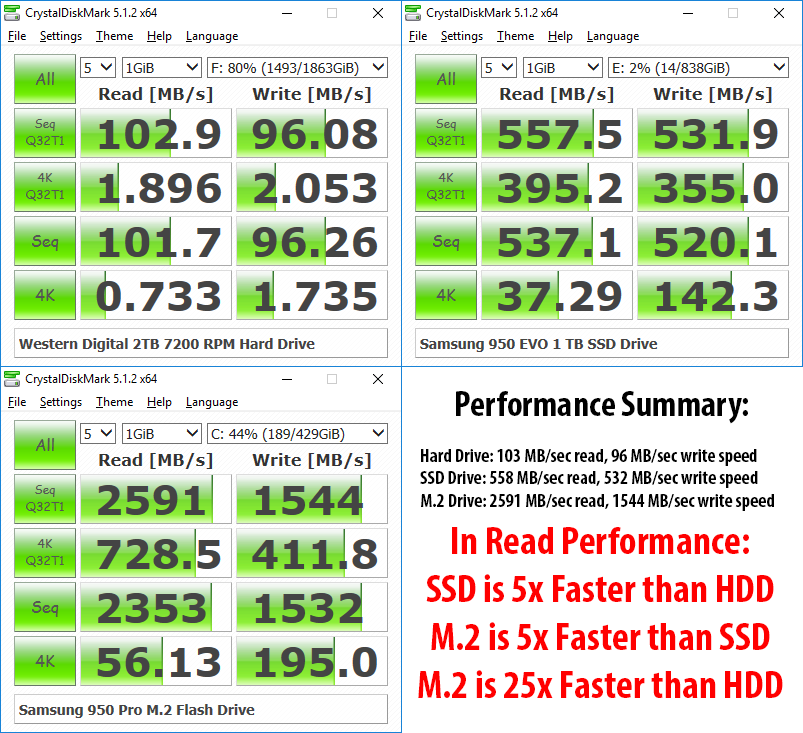
Very good speed! That’s about 110 MB per second, equivalent to a hard disk.
What this would be? To use dynamic libraries instead of sources?
-
AuthorPosts